Working with experimental data requires reading from and writing to multiple data formats, with researchers commonly having to write custom scripts to convert data from one format to another. However, and as discussed in our “e-WindLidar: making wind lidar data FAIR” report, at the right level of abstraction a common data model can be defined to describe all measured data. As such, we propose a modular data converter that enables setting up readers and writers in an any-to-any fashion, and can be configured to attach all sorts of metadata contributing to making its output data more FAIR.
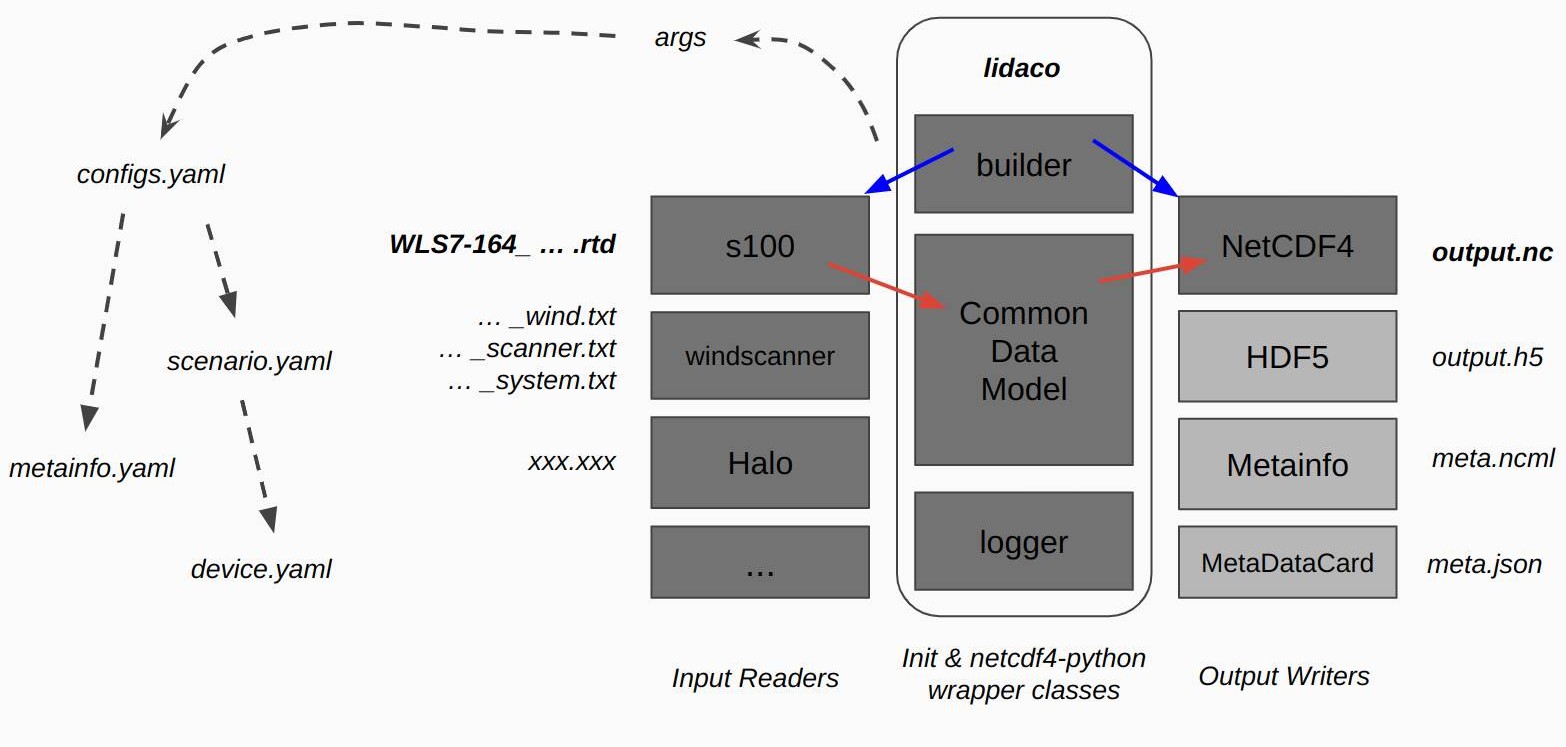
LIDACO (LIdar DAta COnverter) is a Python library and executable that enables a modular writing of FAIR lidar data converters for various types of lidars. As such, you can use it directly from the terminal, or include it in your projects. When using it a configuration (file) must be specified, which includes information about the Reader used to import the data from input files and the Writer used to write the output file(s). Lidaco configuration system is hierarchical to motivate the configurations reusability. As such, each configuration file can import other configuration files. With this mechanism you can to split your configurations into devices, scenarios, campaigns and so on. And associate the appropriate metadata with at the corresponding level.
Lidaco works on datasets that can be described using the unidata Common Data Model and e-WindLidar standard. It can be used to process single files or entire folders. Currently, Lidaco supports out of the box input data recorded by: Galion, WLS70, Windcube v1, Windcube v2, Windcube 100s, 200s and 400s, Long-range WindScanner and ZephIR300; and can export MetadataCard, NcML and netCDF4. However, given its modular design, users can write their on reader/writers. The converter and detail description on how to use it together with practical examples can be found at the e-WindLidar public GitHub repository. Check the link on the top of the page.