Recently, several morphologies, each with its advantages, have been proposed for the GelSight high-resolution tactile sensors. However, existing simulation methods are limited to flat-surface sensors, which prevents the usage of the newer sensors with non-flat morphologies in Sim2Real experiments. In this work, we extend our previously proposed GelSight simulation method, which was developed for flat-surface sensors, and propose a novel method for curved sensors. Particularly we address the simulation of light rays travelling through the curved tactile membrane in the form of geodesic paths. The method is validated by simulating our finger-shaped GelTip[1] sensor and comparing the generated synthetic tactile images against the corresponding real images. Our extensive experiments show that combining the illumination generated from the geodesic paths, with a background image from the real sensor, produces the best results when compared to the lighting generated by direct linear paths in the same conditions. As the method is parameterized by the sensor mesh, it can be applied, in principle, to simulate a tactile sensor of any morphology. The proposed method not only unlocks simulating existing optical tactile sensors of complex morphologies but also enables experimenting with sensors of novel morphologies, before the fabrication of the real sensor.

Simulation method
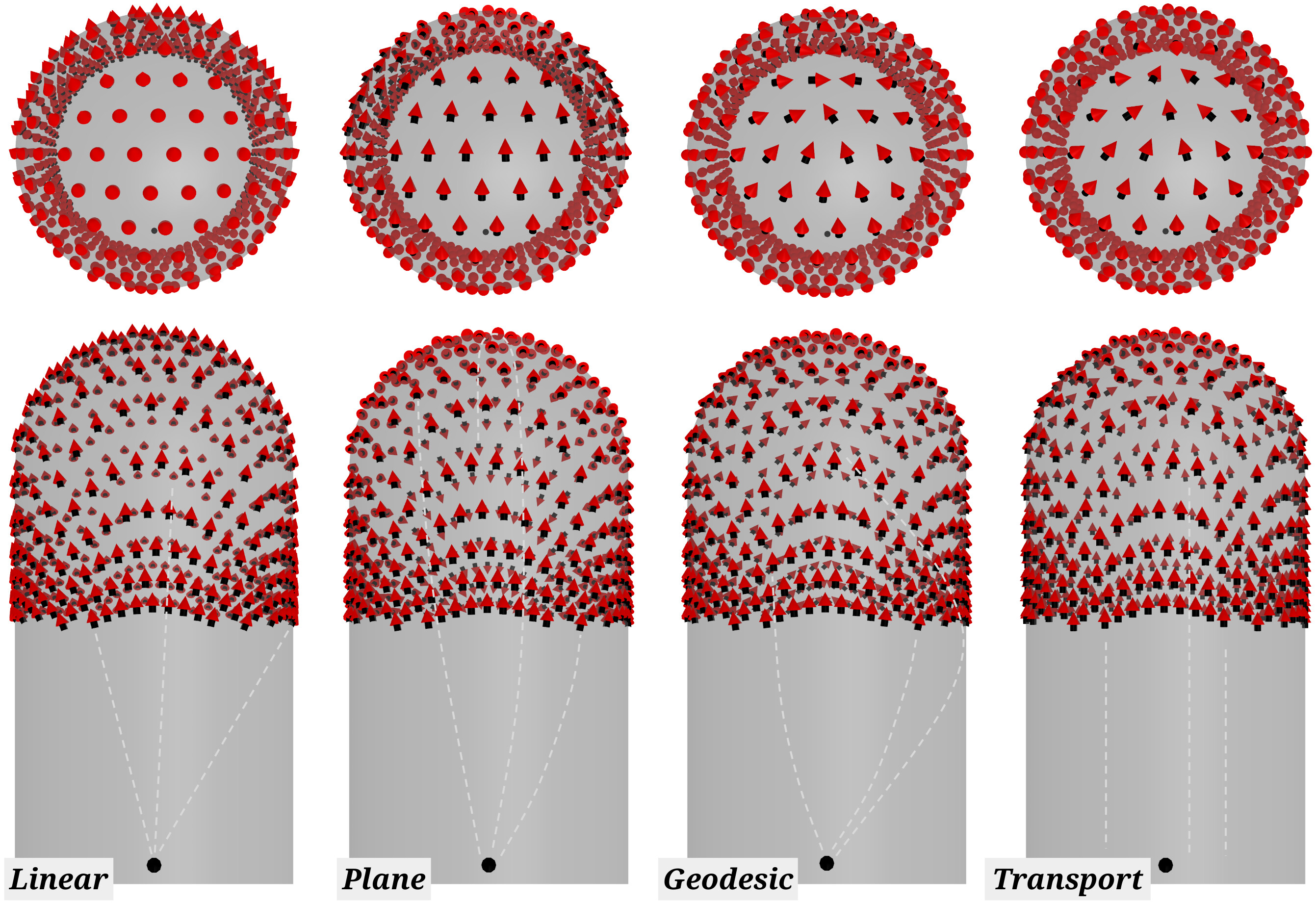
Starting from our previous simulation method for flat GelSight sensors[2] additional steps are considered to address sensors of curved geometry, where the light travels through its curved membrane. Particularly, we address the sensor internal illumination, that for flat sensors is a constant vector field, starting on the LEDs / membrane edge and being tangent to the flat surface. For curved sensors, we consider the geodesic, i.e., the shortest path on a curved surface, as a reasonable path for the light to travel in the membrane. Four alternatives are considered for computing the light field: Linear, Plane, Geodesic and Transport. Linear is a baseline radial light field, originating from a point light source. Plane is a naïve approach for computing the geodesic path, based on the intersection of a plane that passes through the light source, with the sensor mesh. Geodesic and Transport are publicly available implementations for the computation of geodesic paths and vector transport over meshes (Pygeodesic and Transport respectively). Since the light within the entire sensor is constant, we can pre-compute it beforehand. This way, the method can be run online. The overall approach consists of two steps: light fields are firstly computed offline; then, using the computed light fields, the simulation model is run online for each frame of the sensor simulation. The online simulation model consists of three main steps: 1) smoothing of the raw depth map, captured from the simulation environment, to mimic the elastic deformation of the real sensor; 2) mapping of the smoothed depth map onto a point-cloud in the camera coordinates frame; 3) generation of the tactile image using Phong’s reflection model and the pre-computed light fields.

Experiments
To evaluate our method, we collect aligned datasets of RGB tactile image with the real setup and depth-maps with the corresponding simulation, by tapping 8 3D printed objects[3] against the sensor, as shown in Figure 1. The data collection motions consist of equidistant and perpendicular taps on 3 straight paths along the longer axis of the sensor, from the tip to its base. The printers and sensors are controlled sing Yarok[2], ensuring repeatability between environments.
Quantitative analysis. For each light field, we generate the corresponding version of the synthetic RGB dataset, and compare it against real aligned correspondences, as shown in Figure 4. As reported in the paper, the Linear light field results in a better Structural Similarity (SSIM) of 0.84, when no ambient light is considered. However, if either a solid ambient illumination or the background image from the real sensor is used, then the Plane, Geodesic and Transport methods produce the best results, with a high SSIM of 0.93. This directly comes from the fact that the Plane, Geodesic and Transport methods do not produce any illumination in areas that are not being deformed by a contact, which contrasts with the Linear method that generates bright gradients throughout the entire sensor surface, as highlighted in Figure 3.


Sim2Real transfer. The real and simulation RGB datasets (using the geodesic light-field) are split into equal training (80%) and validation (20%) splits, and a ResNet is optimized. We find that, in general, performing these tasks with the simulated images (Sim2Sim) results in better results than the corresponding Real2Real cases. One possible reason could be that with the real sensor, the contact forces between the in-contact object and the sensor result in some bending of the sensor membrane and consecutive weaker imprints, as noticeable in the examples shown in Figure 4. On the other hand, while the Extended dataset and cropping of centred patches positively contribute to a reduction in the Sim2Real gap, the Sim2Real gap is still significant: with the model trained with the simulated data achieving only a maximum classification accuracy of 50.0%, in the classification task, versus the 64.3% obtained by the model trained with the real data. In the Sim2Real contact localisation, the model obtains a minimum localisation error of 11.8mm, worse than the 8.4mm obtained by the model trained with real data.
Conclusions
We proposed a novel approach for simulating GelSight sensors of curved geometry, such as the GelTip. The specific considerations of the light trajectories within the tactile membrane help us in better verify whether our assumptions about the real sensor are true. For instance, with the analysis of different types of light fields, we verify that tactile images captured by the existing GelTip sensors contain a high degree of light that does not travel parallel to the sensor surface, as idealised by the early GelSight working principle. In the future, we will compare the tactile images obtained from a real sensor fabricated using the morphology design optimised in the simulation, and also apply our proposed simulation model in Sim2Real learning for tasks like robot grasping and manipulation with optical tactile sensing.