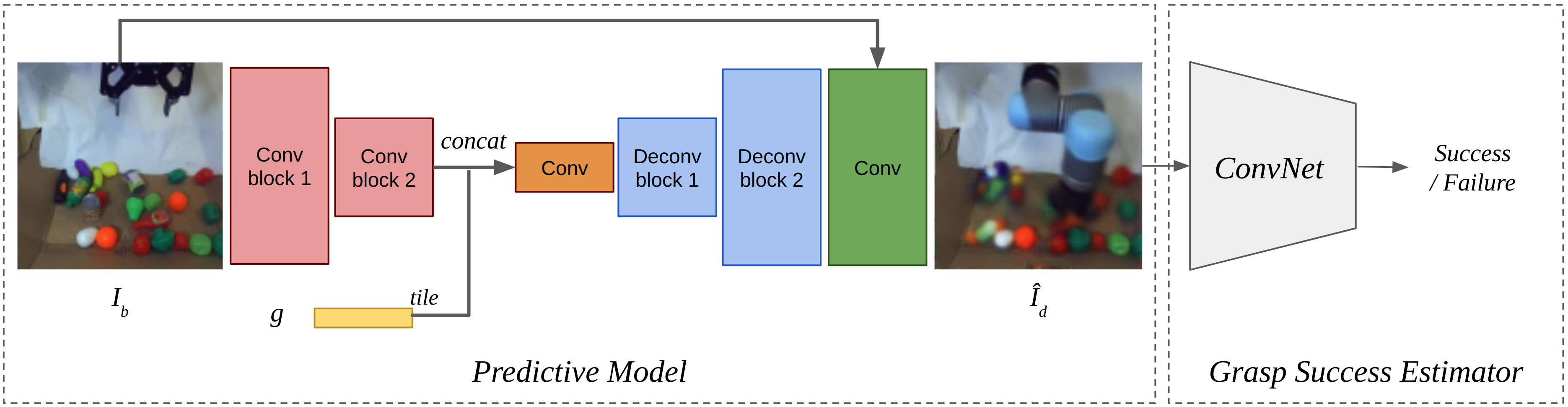
To address the challenging problem of grasping objects in cluttered environments, recent works have proposed training Deep Learning models to predict the success of candidate grasps, from large datasets of monocular images that are collected and annotated fully autonomously. A smaller group of works have also proposed video predictive models to address non-prehensile tasks. However, none have yet combined these two strategies for addressing the aforementioned grasping problem. In this work, we investigate and compare a self-supervised model-free approach, to estimate the success of a candidate grasp, against the model-based counterpart that exploits a self-supervised predictive model that hallucinates a close-up observation of the gripper when about to grasp an object. This decomposition allows us to split the training process into two distinct phases (future observation predictor and grasp success estimator) and, with that, to exploit more data for supervision, without requiring any additional data annotation, as well as analysing each stage individually. Our experiments demonstrate that despite a model-free ConvNet quickly overfitting to the training dataset, a similar network is able to discriminate failed from successful grasps when the image captured right before the grasp occurs, is considered. Further, our predictive model is able to hallucinate these future observations without requiring a calibrated camera or additional annotations. This work contributes to further highlighting the advantage of task decomposition, and the exploitation of predictive models and unsupervised learning in robotics contexts, where labelling datasets extensively is often not feasible.
Grasps dataset
To evaluate our models, we set up a robotic actuator to collect randomly sampled grasps for 4 days. In total, 24,364 random grasps are collected: 3,789 (15.6%) successful grasps, 16,306 (66.9%) aborted attempts, i.e., the gripper collided against an object while moving, and 4,269 (17.6%) empty grasps. For each grasp, we capture images of the scene for three distinct moments Ib, Id and Ia, as illustrated in Algorithm 1. Since a stereo camera is used, effectively two frames are stored per moment. In this work, we use the two frames to double the dataset size.

Method
Experiments
